Модуль «Пространственные запросы»¶
Модуль  Пространственные запросы позволяет выполнять пространственные запросы (выделять объекты) к объектам целевого слоя по отношению к объектам другого слоя. Модуль использует функционал библиотеки GEOS (Geometry Engine — Open Source).
Пространственные запросы позволяет выполнять пространственные запросы (выделять объекты) к объектам целевого слоя по отношению к объектам другого слоя. Модуль использует функционал библиотеки GEOS (Geometry Engine — Open Source).
Поддерживаются следующие операторы:
Использование модуля¶
В качестве примера найдем регионы Аляски, в которых есть аэропорт. Для этого:
Активируйте модуль «Пространственные запросы» в Менеджере модулей (см. раздел Загрузка основных модулей QGIS) и нажмите на кнопку Пространственные запросы на панели инструментов. Откроется главное окно модуля.
Укажите слой regions в качестве исходного слоя, а слой airports как опорный слой.
Выберите оператор «Содержит» и нажмите [Применить].
В результате мы получим список идентификаторов объектов, удовлетворяющих условию и можем (см. рисунок figure_spatial_query_1).
 Создать слой из выделенных объектов
Создать слой из выделенных объектов
Выбрать идентификатор(ы) из списка и нажать  Создать слой из выделенных объектов
Создать слой из выделенных объектов
Выбрать «Удалить из текущего выделения» в выпадающем списке Результат запроса  .
.
Активировать флажок  Увеличить до объекта или Отладочные сообщения.
Увеличить до объекта или Отладочные сообщения.
Figure Spatial Query 1:

Пространственный запрос — области с аэропортами 
Справка
Краткая информация
Добавляет пространственный индекс в шейп-файл, файловую базу геоданных или класс пространственных объектов SDE. Используйте этот инструмент либо для добавления пространственного индекса к шейп-файлу или классу пространственных объектов, который еще не имеет таковых, либо для перепостроения существующего пространственного индекса.Советы по использованию.
Использование
ArcGIS использует пространственные индексы для быстрого поиска объектов в классах пространственных объектов. Определение пространственного объекта, выбор объектов путем наведения и растягивания окна, а также перемещение и масштабирование – все это обязывает ArcMap использовать пространственный индекс для поиска объектов. Пространственный индекс определяется путем использования виртуальных сеток, которые накладываются на экстент пространственных объектов в классе объектов, аналогично индексным сеткам на маршрутных картах в путеводителях.
Добавление нового пространственного индекса в класс пространственных объектов ArcSDE довольно сильно загружает сервер. Не следует делать это с большими классами пространственных объектов, если к серверу подключено большое количество пользователей.
Синтаксис
Класс пространственных объектов SDE, класс объектов файловой базы геоданных или шейп-файл, в которые должен быть добавлен пространственный индекс, или в которых он должен быть повторно построен.
Параметры Пространственная сетка 1, 2 и 3 (Spatial Grid 1, 2, and 3) применяются только к файловой базе геоданных и к конкретным классам пространственных объектов базы геоданных ArcSDE. Если вы не знакомы с установкой размеров сетки, оставьте эти параметры на 0,0,0, и ArcGIS вычислит оптимальный для вас размер.
Размер ячейки второй пространственной сетки. Оставьте размер равным 0, если вам нужна только одна сетка. В противном случае, задайте размер по крайней мере в три раза больше, чем Пространственная сетка 1 (Spatial Grid 1).
Размер ячейки третьей пространственной сетки. Оставьте размер равным 0, если вам нужно только две сетки. В противном случае, задайте размер, по крайней мере, в три раза больше, чем Пространственная сетка 2 (Spatial Grid 2).
Пример кода
Пример 1 функции AddSpatialIndex (окно Python)
Пример (окно Python) Пример скрипта Python для выполнения функции Добавить пространственный индекс (Add Spatial Index) с запуском из окна Python в ArcGIS.
Пример 2 функции AddSpatialIndex (автономный скрипт Python)
На следующем скрипте Python демонстрируется, как использовать функцию Добавить пространственный индекс (Add Spatial Index) в автономном скрипте.
6.4. Занятие: Пространственная статистика¶
Урок подготовлен Linfiniti и S Motala (Технологический университет Кейп-Пенинсула).
Пространственная статистика позволяет вам сделать анализ и понять, что происходит в данном наборе векторных данных. QGIS имеет множество полезных инструментов для статистического анализа.
6.4.1.  Идем дальше: Создаем тестовый набор данных¶
Идем дальше: Создаем тестовый набор данных¶
 Идем дальше: Создаем тестовый набор данных¶
Идем дальше: Создаем тестовый набор данных¶Мы создадим случайный набор точек и получим набор данных для работы.
Чтобы это сделать вам понадобится набор данных полигона, чтобы определить местность, в которой вы хотите создать точки.
Мы будем использовать площадь, покрытую улицами.
Начните новый проект.
Вы возможно обнаружите, что слой SRTM DEM имеет другую ССК, которая отличается от слоя дорог. QGIS пере-проецирует оба слоя в одной ССК. Для следующих упражнений эта разница не имеет значения, но вы можете пере-проецировать (как было показано ранее в этом модуле).
Используйте инструмент Vector Geometry ► Minimum bounding geometry для создания местности, привязав все дороги, выбрав Convex Hull в качестве Geometry Type :
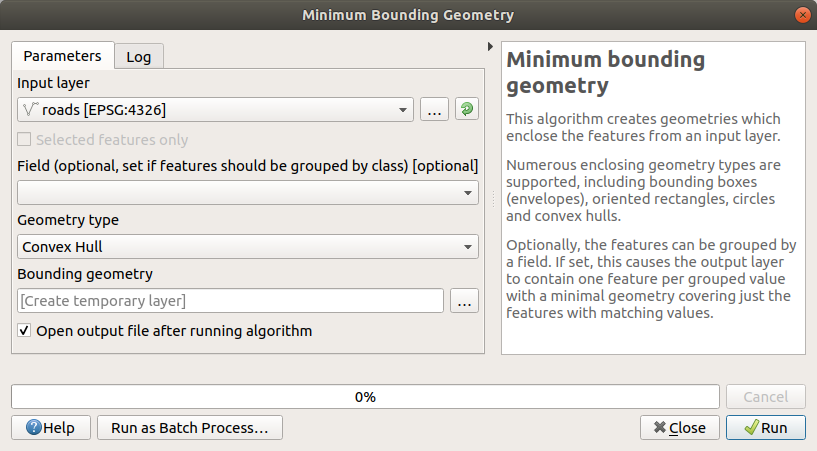
Как известно, если вы не укажете выход, Обработка создаст временные слои. Вы можете сразу сохранить слои или сделать это позже.
6.4.1.1. Создание случайных точек¶
Создайте 100 случайных точек в этой местности, используя инструмент в Vector Creation ► Random points in layer bounds с минимальным расстоянием 0.0 :
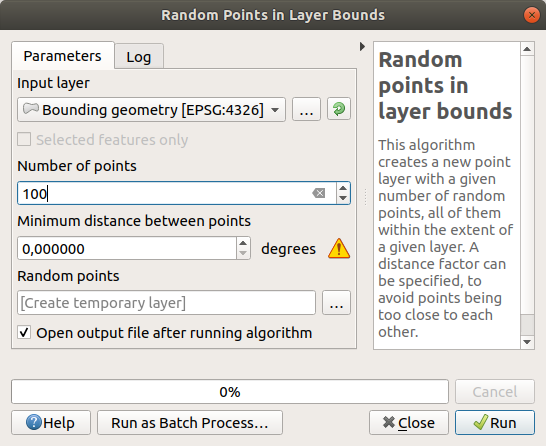
Желтый предупреждающий знак говорит вам, что этот параметр относится к расстояниям. Слой Bounding geometry находится в географической системе координат и алгоритм просто напоминает вам об этом. В этом примере мы не будем использовать этот параметр, поэтому вы можете его проигнорировать.
Если надо, переместите сгенерированные случайные точки в верхнюю часть условного обозначения, чтобы лучше их увидеть:
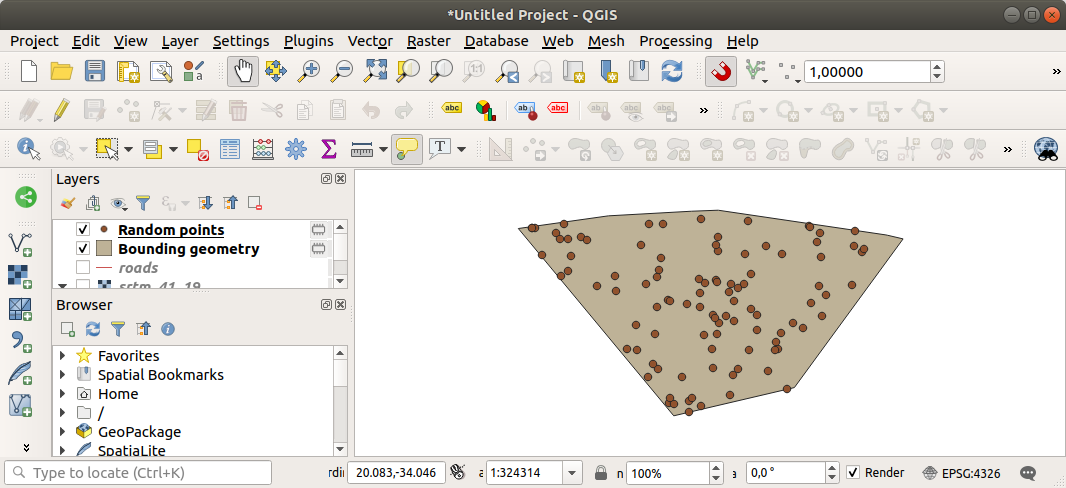
6.4.1.2. Выборка данных¶
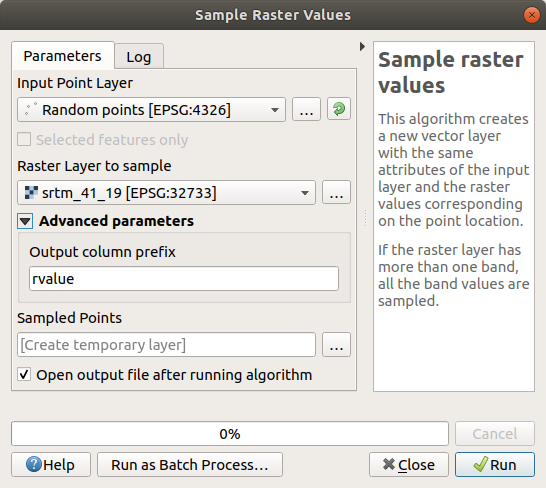
Возможный образец слоя показан здесь:
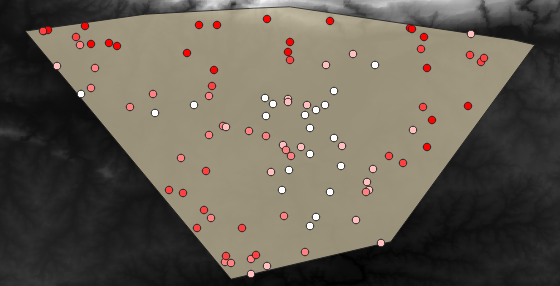
Выборочные точки классифицируются с использованием поля rvalue_1 так, чтобы красные точки находились на большей высоте.
Вы будете использовать этот слой для остальных статистических упражнений.
6.4.2. Идем дальше: Базовая статистика¶
Вам теперь надо получить базовую статистику для этого слоя.
В появившемся диалоговом окне укажите слой Sampled Points в качестве источника.
Выберите поле rvalue_1 в поле со списком полей. Это поле, для которого вы будете рассчитывать статистику.
Панель Statistics автоматически обновится с расчетными статданными:
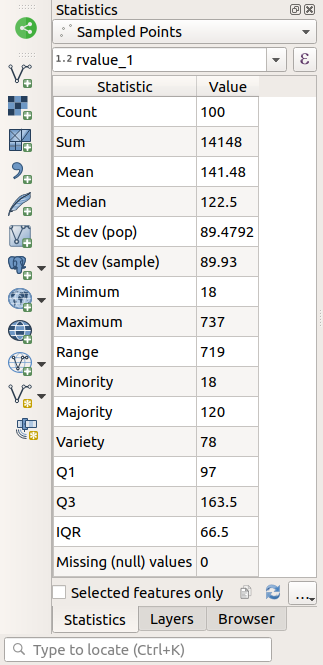
Вы можете скопировать значения, нажав на кнопку  Copy Statistics To Clipboard и вставив результаты в таблицу.
Copy Statistics To Clipboard и вставив результаты в таблицу.
Закройте панель Statistics когда закончите.
Появятся много команд, связанных со статистикой:
Количество выборок /значений.
St Dev (pop)/Стандартное отклонение
Стандартное отклонение. Указывает, насколько близко значения сгруппированы вокруг среднего. Чем меньше стандартное отклонение, тем ближе значения к среднему.
Разница между минимальным и максимальным значениями.
Первый квартиль данных.
Третий квартиль данных.
Missing (null) values/Пропущенные (нулевые) значения
Количество пропущенных значений.
6.4.3. Идем дальше: Вычисляем статистические данные относительно расстояний между точками¶
Создайте новый временный точечный слой.
Зайдите в режим редактирования и оцифруйте три точки где-нибудь среди других точек.
В качестве альтернативы вы можете использовать тот же метод генерации случайных точек, как ранее мы делали, но надо указать только три точки.
Сохраните ваш новый слой как distance_points в том формате, к котором вам хочется.
Чтобы получить статистику расстояний между точками в двух слоях необходимо сделать следующее:
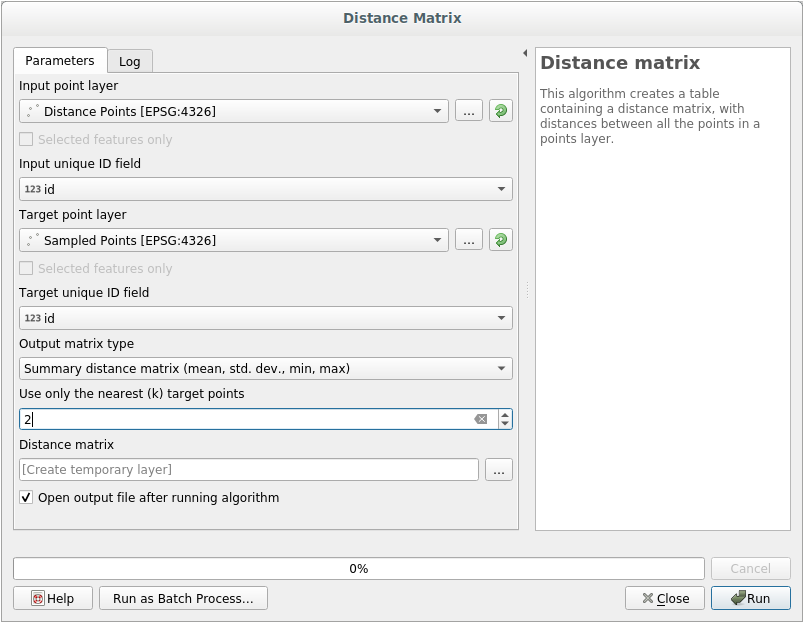
Если хотите, вы можете сохранить выходной слой как файл или просто можете запустить алгоритм и сохранить временный выходной слой позже.
Кликните на кнопку Run чтобы получить слой матрицы расстояний.
Откройте таблицу с атрибутами сгенерированного слоя: значения относятся к расстояниям между объектами distance_points и их двумя ближайшими точками в слое Sampled Points :
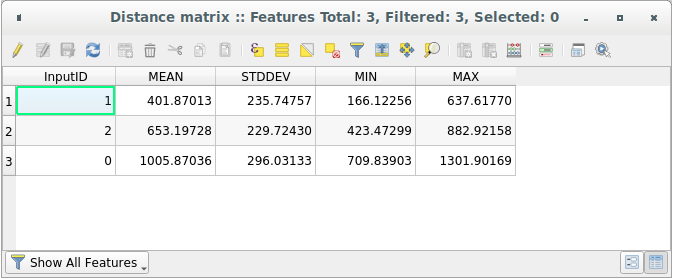
С помощью этих параметров инструмент Матрица расстояний рассчитает статистику расстояний для каждой точки входного слоя по отношению к ближайшим точкам целевого слоя. Поля выходного слоя содержат среднее значение, стандартное отклонение, минимальные и максимальные значения в отношении расстояний до ближайших соседних точек входного слоя.
6.4.4. Идем дальше: Анализ методом «ближайший сосед» (внутри слоя)¶
Чтобы выполнить анализ методом «ближайший сосед» точечного слоя, необходимо сделать следующее:
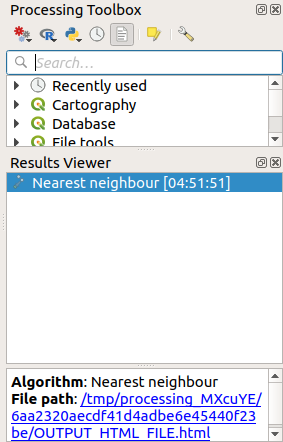
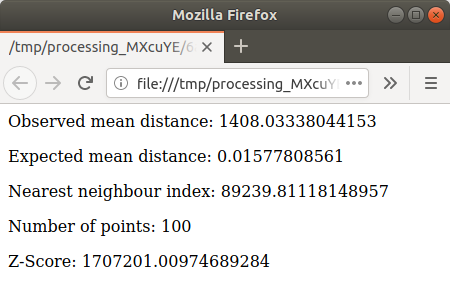
Кликните синюю ссылку, чтобы открыть страницу html с результатами:
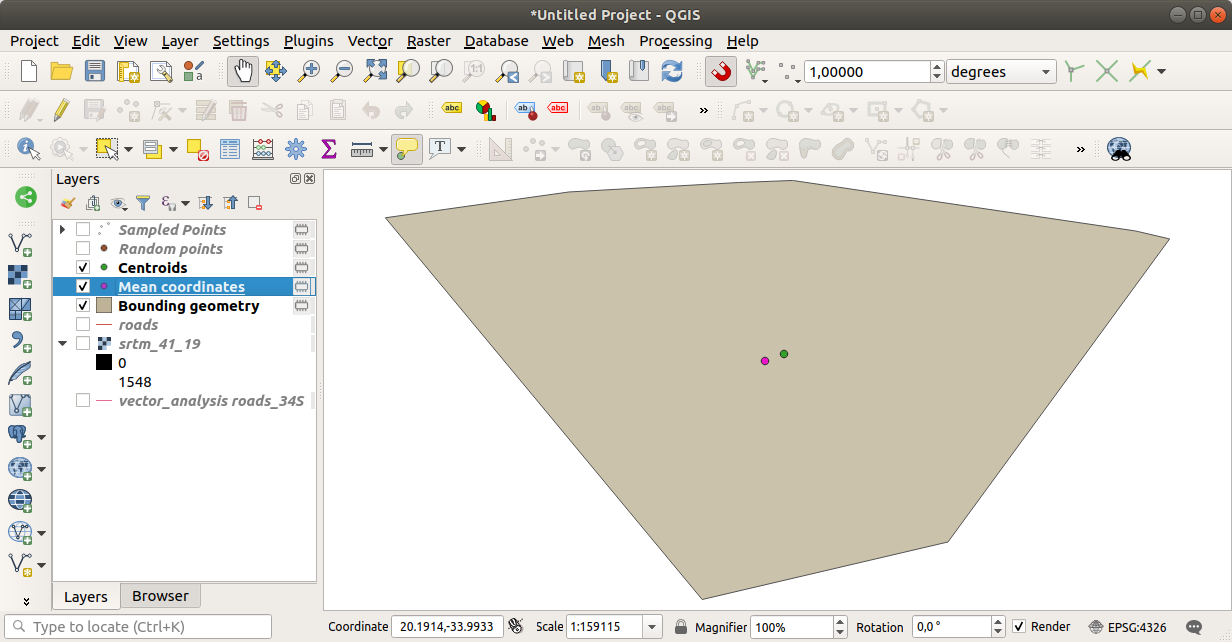
6.4.5. Идем дальше: Средние координаты¶
Для того, чтобы получить средние координаты набора данных необходимо сделать следующее:
Давайте сравним это с центральной координатой полигона, который был использован для создания случайной выборки.
В появившемся диалоговом окне выберите Bounding geometry в качестве входного слоя.
Как видите, средние координаты (розовая точка) и центр исследуемой местности (зеленый) не обязательно совпадают.
6.4.6. Идем дальше: Гистограммы изображений¶
Гистограмма набора данных показывает распределение его значений. Самый простой способ показать это в QGIS – через использование гистограммы изображения, которая имеется в диалоговом окне Layer Properties любого слоя изображения (набор растровых данных).

Более подробную информацию можно получить о слое нажав на вкладку Information (среднее и максимальное значения являются расчетными и могут быть неточными).
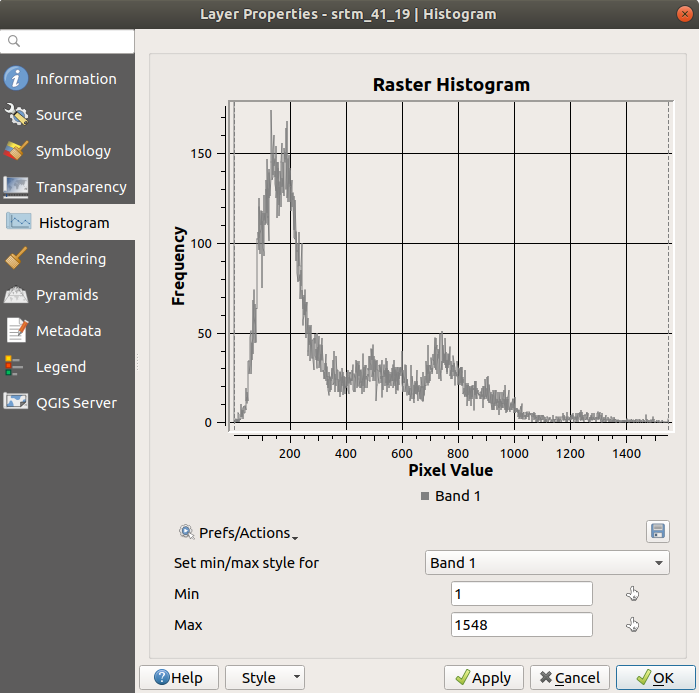
Помните, что гистограмма показывает вам распределение значений и не все значения обязательно должны отображаться на графике.
6.4.7. Идем дальше: Пространственная интерполяция¶
И наконец, кликните на кнопку Run и подождите до окончания обработки.
Закройте диалоговое окно.
Вы сможете сравнить исходный набор данных (слева) с тем, который был построен на базе наших точек выборки (справа). Ваш набор данных может выглядеть иначе из-за случайного расположения точек.
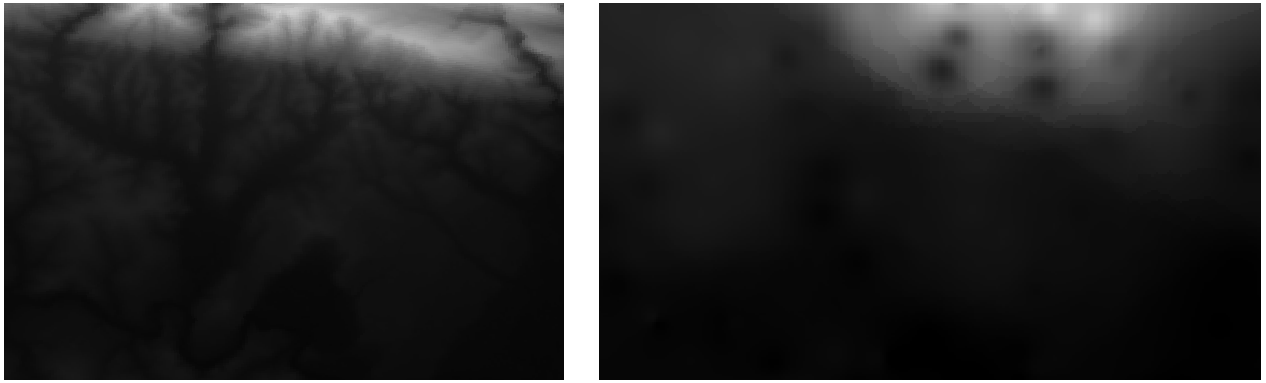
Как вы можете видеть, 100 выборочных точек недостаточно, чтобы получить подробное представление о местности. Вы получите только очень общее представление, но оно может вводить в заблуждение.
6.4.8. Попробуйте сами: Различные методы интерполяции¶
 Попробуйте сами: Различные методы интерполяции¶
Попробуйте сами: Различные методы интерполяции¶Следуйте описанному выше процессу для того, чтобы создать набор из 10 000 случайных точек.
Если точек действительно много, обработка может занять много времени.
Используйте эти точки для того сделать выборку исходной DEM / Цифровой модели рельефа.
Используйте инструмент Grid (IDW with nearest neighbor searching) в этом наборе данных.
Результаты (в зависимости от расположения ваших случайных точек) будут примерно такими:

Это более улучшенное представление ландшафта, так как плотность выборочных точек выше. Помните, что чем больше выборка, тем лучше результат.
6.4.9. В заключении¶
У QGIS есть ряд инструментов для анализа пространственных статистических свойств набора данных.
6.4.10. Что дальше?¶
Теперь, после того как мы рассмотрели векторный анализ, почему бы не посмотреть, что можно сделать с растрами? Этим мы и займемся в следующем модуле!
© Copyright 2002-now, QGIS project. Обновлено: сент. 18, 2021 09:45.
11. Пространственный анализ (интерполяция)¶
Understanding of interpolation as part of spatial analysis
Point data, interpolation method, Inverse Distance Weighted, Triangulated Irregular Network
11.1. Обзор¶
Spatial analysis is the process of manipulating spatial information to extract new information and meaning from the original data. Usually spatial analysis is carried out with a Geographic Information System (GIS). A GIS usually provides spatial analysis tools for calculating feature statistics and carrying out geoprocessing activities as data interpolation. In hydrology, users will likely emphasize the importance of terrain analysis and hydrological modelling (modelling the movement of water over and in the earth). In wildlife management, users are interested in analytical functions dealing with wildlife point locations and their relationship to the environment. Each user will have different things they are interested in depending on the kind of work they do.
11.2. Spatial interpolation in detail¶
Spatial interpolation is the process of using points with known values to estimate values at other unknown points. For example, to make a precipitation (rainfall) map for your country, you will not find enough evenly spread weather stations to cover the entire region. Spatial interpolation can estimate the temperatures at locations without recorded data by using known temperature readings at nearby weather stations (see figure_temperature_map). This type of interpolated surface is often called a statistical surface. Elevation data, precipitation, snow accumulation, water table and population density are other types of data that can be computed using interpolation.
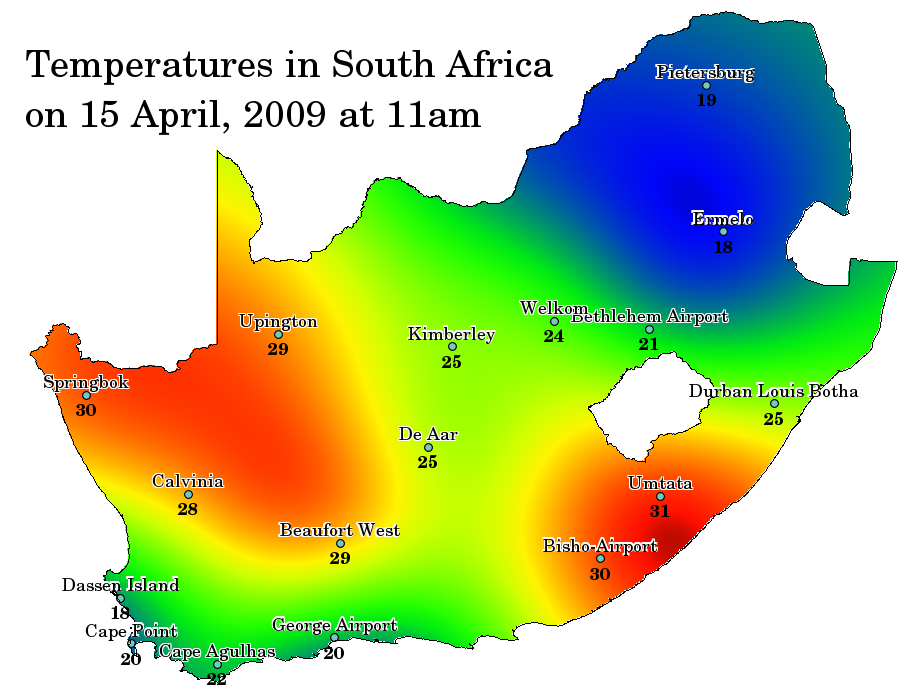
Рис. 11.40 Temperature map interpolated from South African Weather Stations. ¶
Because of high cost and limited resources, data collection is usually conducted only in a limited number of selected point locations. In GIS, spatial interpolation of these points can be applied to create a raster surface with estimates made for all raster cells.
In order to generate a continuous map, for example, a digital elevation map from elevation points measured with a GPS device, a suitable interpolation method has to be used to optimally estimate the values at those locations where no samples or measurements were taken. The results of the interpolation analysis can then be used for analyses that cover the whole area and for modelling.
There are many interpolation methods. In this introduction we will present two widely used interpolation methods called Inverse Distance Weighting (IDW) and Triangulated Irregular Networks (TIN). If you are looking for additional interpolation methods, please refer to the „Further Reading“ section at the end of this topic.
11.3. Inverse Distance Weighted (IDW)¶
In the IDW interpolation method, the sample points are weighted during interpolation such that the influence of one point relative to another declines with distance from the unknown point you want to create (see figure_idw_interpolation).
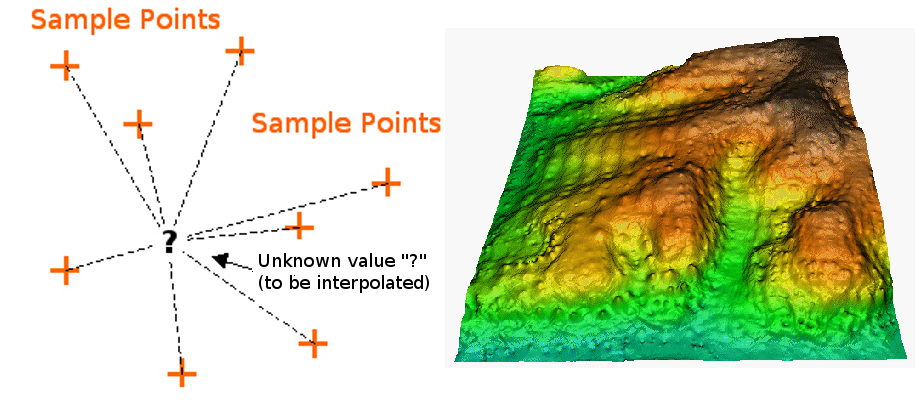
Рис. 11.41 Inverse Distance Weighted interpolation based on weighted sample point distance (left). Interpolated IDW surface from elevation vector points (right). Image Source: Mitas, L., Mitasova, H. (1999). ¶
Weighting is assigned to sample points through the use of a weighting coefficient that controls how the weighting influence will drop off as the distance from new point increases. The greater the weighting coefficient, the less the effect points will have if they are far from the unknown point during the interpolation process. As the coefficient increases, the value of the unknown point approaches the value of the nearest observational point.
It is important to notice that the IDW interpolation method also has some disadvantages: the quality of the interpolation result can decrease, if the distribution of sample data points is uneven. Furthermore, maximum and minimum values in the interpolated surface can only occur at sample data points. This often results in small peaks and pits around the sample data points as shown in figure_idw_interpolation.
In GIS, interpolation results are usually shown as a 2 dimensional raster layer. In figure_idw_result, you can see a typical IDW interpolation result, based on elevation sample points collected in the field with a GPS device.
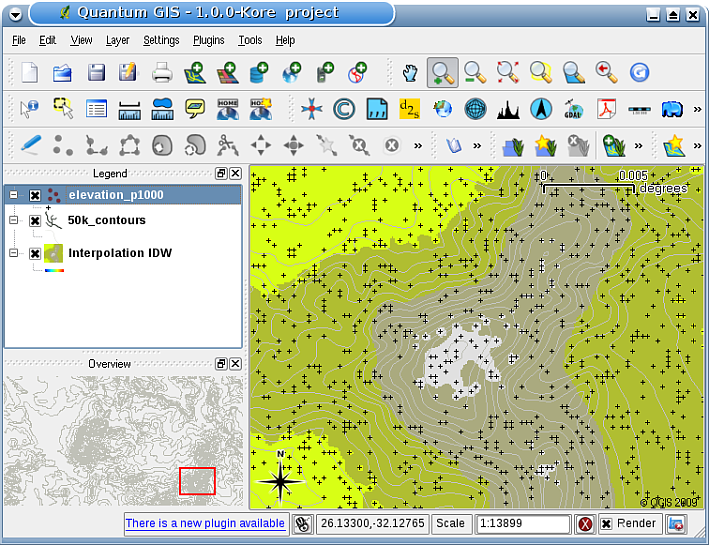
Рис. 11.42 IDW interpolation result from irregularly collected elevation sample points (shown as black crosses). ¶
11.4. Triangulated Irregular Network (TIN)¶
TIN interpolation is another popular tool in GIS. A common TIN algorithm is called Delaunay triangulation. It tries to create a surface formed by triangles of nearest neighbour points. To do this, circumcircles around selected sample points are created and their intersections are connected to a network of non overlapping and as compact as possible triangles (see figure_tin_interpolation).
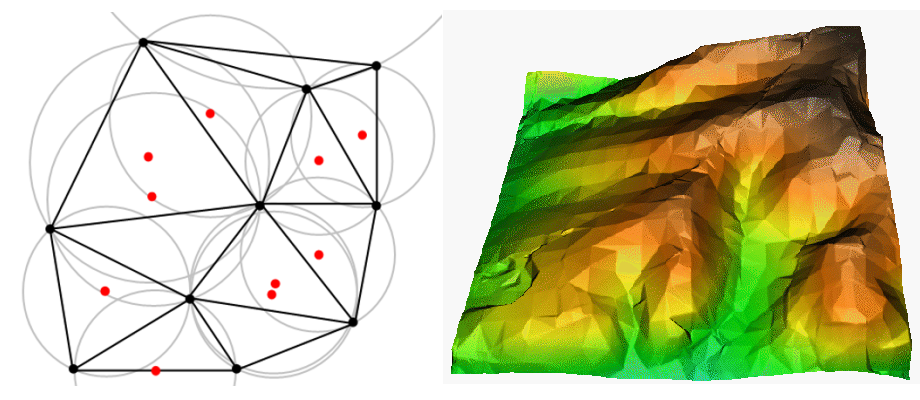
Рис. 11.43 Delaunay triangulation with circumcircles around the red sample data. The resulting interpolated TIN surface created from elevation vector points is shown on the right. Image Source: Mitas, L., Mitasova, H. (1999). ¶
The main disadvantage of the TIN interpolation is that the surfaces are not smooth and may give a jagged appearance. This is caused by discontinuous slopes at the triangle edges and sample data points. In addition, triangulation is generally not suitable for extrapolation beyond the area with collected sample data points (see figure_tin_result ).
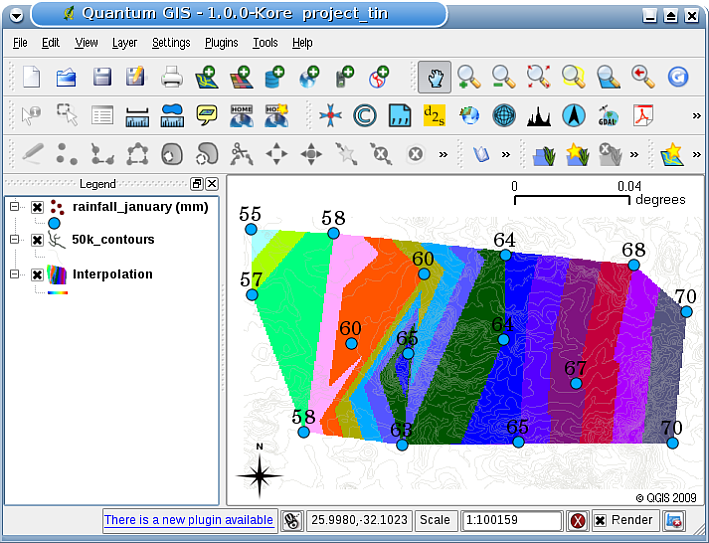
Рис. 11.44 Delaunay TIN interpolation result from irregularly collected rainfall sample points (blue circles) ¶
11.5. Основные ошибки / о чём стоит помнить¶
It is important to remember that there is no single interpolation method that can be applied to all situations. Some are more exact and useful than others but take longer to calculate. They all have advantages and disadvantages. In practice, selection of a particular interpolation method should depend upon the sample data, the type of surfaces to be generated and tolerance of estimation errors. Generally, a three step procedure is recommended:
Evaluate the sample data. Do this to get an idea on how data are distributed in the area, as this may provide hints on which interpolation method to use.
Apply an interpolation method which is most suitable to both the sample data and the study objectives. When you are in doubt, try several methods, if available.
Compare the results and find the best result and the most suitable method. This may look like a time consuming process at the beginning. However, as you gain experience and knowledge of different interpolation methods, the time required for generating the most suitable surface will be greatly reduced.
11.6. Other interpolation methods¶
Although we concentrated on IDW and TIN interpolation methods in this worksheet, there are more spatial interpolation methods provided in GIS, such as Regularized Splines with Tension (RST), Kriging or Trend Surface interpolation. See the additional reading section below for a web link.
11.7. Что мы узнали?¶
Interpolation uses vector points with known values to estimate values at unknown locations to create a raster surface covering an entire area.
The interpolation result is typically a raster layer.
It is important to find a suitable interpolation method to optimally estimate values for unknown locations.
IDW interpolation gives weights to sample points, such that the influence of one point on another declines with distance from the new point being estimated.
TIN interpolation uses sample points to create a surface formed by triangles based on nearest neighbour point information.
11.8. Попробуйте сами!¶
Вот некоторые идеи для заданий:
The Department of Agriculture plans to cultivate new land in your area but apart from the character of the soils, they want to know if the rainfall is sufficient for a good harvest. All the information they have available comes from a few weather stations around the area. Create an interpolated surface with your learners that shows which areas are likely to receive the highest rainfall.
The tourist office wants to publish information about the weather conditions in January and February. They have temperature, rainfall and wind strength data and ask you to interpolate their data to estimate places where tourists will probably have optimal weather conditions with mild temperatures, no rainfall and little wind strength. Can you identify the areas in your region that meet these criteria?
11.9. Стоит учесть¶
If you don’t have a computer available, you can use a toposheet and a ruler to estimate elevation values between contour lines or rainfall values between fictional weather stations. For example, if rainfall at weather station A is 50 mm per month and at weather station B it is 90 mm, you can estimate, that the rainfall at half the distance between weather station A and B is 70 mm.
11.10. Дополнительная литература¶
Книги:
Chang, Kang-Tsung (2006). Introduction to Geographic Information Systems. 3rd Edition. McGraw Hill. ISBN: 0070658986
DeMers, Michael N. (2005): Fundamentals of Geographic Information Systems. 3rd Edition. Wiley. ISBN: 9814126195
Mitas, L., Mitasova, H. (1999). Spatial Interpolation. In: P.Longley, M.F. Goodchild, D.J. Maguire, D.W.Rhind (Eds.), Geographical Information Systems: Principles, Techniques, Management and Applications, Wiley.
Веб-сайты:
The QGIS User Guide also has more detailed information on interpolation tools provided in QGIS.
11.11. Что дальше?¶
This is the final worksheet in this series. We encourage you to explore QGIS and use the accompanying QGIS manual to discover all the other things you can do with GIS software!
© Авторские права 2002-now, QGIS project Обновлено: дек. 09, 2020 10:43.



