Значение слова «промежуточный»

1. Образующий собой промежуток, пространство между чем-л. Промежуточное расстояние. □ — Сейчас линию батальона отделяет от противника промежуточная полоса шириной до пятнадцати километров. Бек, Волоколамское шоссе.
2. Находящийся между двумя или несколькими предметами или явлениями, не начальный и не конечный в ряду чего-л. Промежуточная стадия. □ Расчет, что он выйдет на какой-нибудь промежуточной станции до Выборга — не оправдался. Мамин-Сибиряк, Падающие звезды. Меркулов переступал ногами осторожно и почтительно, а на промежуточных площадках вежливо отдыхал, хотя усталости не чувствовал. Л. Андреев, Весенние обещания. || Занимающий срединное положение между противоположными явлениями. Между пролетариатом и буржуазией существует еще класс людей, склоняющихся то в одну, то в другую сторону; так было всегда и во всех революциях, и абсолютно невозможно, чтобы в капиталистическом обществе, где пролетариат и буржуазия образуют два враждебных лагеря, не существовало между ними промежуточных слоев. Ленин, I конгресс Коммунистического Интернационала. Или погибнуть, или завоевать себе право устроить жизнь по правде — так был поставлен вопрос, и все промежуточные, компромиссные решения отвергнуты. А. Н. Толстой, Кровь народа. || Биол. Такой, который не может быть отнесен ни к одной из определенных категорий, сочетает различные черты, свойственные разным категориям. Промежуточные виды. Промежуточные формы растений.
Источник (печатная версия): Словарь русского языка: В 4-х т. / РАН, Ин-т лингвистич. исследований; Под ред. А. П. Евгеньевой. — 4-е изд., стер. — М.: Рус. яз.; Полиграфресурсы, 1999; (электронная версия): Фундаментальная электронная библиотека
ПРОМЕЖУ’ТОЧНЫЙ [шн], ая, ое. 1. Образующий собой промежуток, пространство между чем-н. П. участок земли. Промежуточное расстояние. 2. перен. Не начальный и не конечный в ряду чего-н., находящийся посередине между двумя или несколькими явлениями. Промежуточная стадия. Промежуточные процессы. Промежуточные цифры. 3. перен. Такой, к-рый не может быть отнесен к какому-н. из противоположных явлений или совмещающий в себе противоположные либо различные черты. Промежуточные виды (биол.). || Занимающий среднее положение между противоположными явлениями, имеющий двойственную природу. Промежуточные слои буржуазного общества (мелкая буржуазия, интеллигенция).
Источник: «Толковый словарь русского языка» под редакцией Д. Н. Ушакова (1935-1940); (электронная версия): Фундаментальная электронная библиотека
промежу́точный
1. образующий собою промежуток, пространство между чем-либо
2. находящийся, расположенный в промежутке между чем-либо; не основной, не главный ◆ Развитие от протоморфа к акроморфу идёт через ряд мезоморфов, т. е. ряд промежуточных этапов. Ж.Г. Абдуллаев, Н.Д. Сулейманов, «Проблемы сравнительно-исторического исследования морфологии языков Дагестана», 1992 г.
3. перен. находящийся между двумя или несколькими явлениями; переходный
Делаем Карту слов лучше вместе
 Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я стал чуточку лучше понимать мир эмоций.
Вопрос: погреться — это что-то нейтральное, положительное или отрицательное?
Умная нормализация данных: категориальные и порядковые данные, “парные” признаки
Эта статья внеплановая. В прошлый раз я рассматривал нюансы и проблемы различных методов нормализации данных. И только после публикации понял, что не упомянул некоторые важные детали. Кому-то они покажутся очевидными, но, по-моему, лучше сказать об этом явно.
Нормализация категориальных данных
Чтобы не засорять текст базовыми вещами, я буду считать, что Вы знаете, что такое категориальные и порядковые данные, и чем они отличаются от остальных.
Очевидно, что любая нормализация может выполняться только для числовых данных. Соответственно, если для дальнейшей работы Вашему алгоритму/программе подходят только числа, то необходимо преобразовать все остальные типы к ним.
С категориальными данными всё просто. Если целью является не просто кодировка (шифровка) значений какими-то числами, то единственный доступный вариант — это представить их в виде значений “1” — “0” (ДА — НЕТ) для каждой возможной категории. Это так называемое one-hot-кодирование. Когда вместо одного категориального признака появится столько новых “булевых” признаков, сколько существует возможных категорий.

Никаких вычислений медиан или средних арифметических, никаких смещений.
Если Вы подготавливаете данные для входа нейронной сети, это именно то, что нужно.
Важно понять, что применять преобразования подобные стандартизации к категориальным/”булевым” признакам как минимум бесполезно, а как максимум — вредно. Поскольку может необоснованно увеличить или уменьшить их интервал значений. Подробнее о важности равенства этих интервалов я писал в прошлый раз.
К тому же, если Вы хотите получить результат, основанный на данных, а не на внутренних особенностях алгоритмов, то даже после преобразования в числовую форму категориальные признаки нельзя использовать как обычные числовые для вычисления “расстояний” между объектами или их “схожести”. Если два объекта отличаются только “наличием черного цвета”, это не значит, что между ними “расстояние” равное некому безразмерному единичному интервалу. Это значит именно то, что у одного есть чёрный цвет, а у другого его нет — и не более того.
Конечно, какой-то результат Вы получите всегда, даже при подходе «не хочу мудрить, пусть будут просто числа 0 и 1». Сомнительный, но получите. Как корректно работать с такими данными, я подробно напишу в следующей статье.
Нормализация порядковых данных
С порядковыми данными немного сложнее. Они занимают “промежуточное” положение между категориальным и относительным (обычными числами) типами данных. И при работе с ними необходимо сделать выбор, к какому из соседних типов их преобразовывать. Без Вашего осознанного решения здесь никак.
Вариант 1. Из порядковых в категориальные. В этом случае теряется информация о порядке значений (что больше). Но если это не является (по Вашему мнению) важным фактором, и особенно, когда возможных значений немного, то вполне приемлемо. На выходе получаем набор категорий, с которыми дальше работаем, как описано выше.
Вариант 2. Преобразование в интервальный тип (обычные числа). В этом случае сохраняется порядок значений, но “добавляется” необоснованная информация о величине разницы между двумя значениями.
До преобразования Вы знали, какие значения больше других, но не могли сказать насколько больше. После — это станет возможным, хотя, повторюсь, без всякого обоснования.
Дальше работаем как с обычными значениями — нормируем и т.д.
“Парные” признаки
Формально такого понятия, конечно, не существует. Я так обозначаю редкую, но заслуживающую внимания ситуацию.
Для начала определение. “Парными” признаками я называю признаки, которые измеряются в одинаковых единицах и вместе описывают единый комбинированный признак. Причем изменения по любому из таких “напарников” равнозначны.
Проще пояснить на примере. Представьте, что у Вас есть набор данных о строениях, размещенных на одной улице города, которая лежит строго с юга на север. Данные самые разные — тип, размер, количество жильцов, цвет и координаты (широта и долгота). И перед Вами стоит задача провести кластерный анализ для выявления групп похожих строений.
“Парными” признаками здесь являются широта и долгота, которые вместе составляют единый признак “координаты”. Временно забудем про остальные признаки и присмотримся к координатам.
Для кластеризации важно определять расстояние между двумя объектами. В нашем случае расстояние рассчитывается по их координатам. И совершенно одинаково, например, отстоит детский садик от стадиона на 100 м вдоль по улице, или он в тех же 100 м через дорогу. Это одинаковые 100 м.
Если на этот нюанс не обращать внимания, то после нормализации ситуация станет такой
Изначальный смысл совершенно исказился. “Расстояние” между зданиями, расположенными через дорогу стало практически таким же большим, как и между домами в начале и конце улицы. Это произошло из-за того, что значения широты и долготы были нормализированы независимо друг от друга.
Решение этой проблемы лежит в определении параметров масштабирования самого “протяженного” признака (в нашем случае долготы) и применения его к всем “парным” признакам.
Да, формально, мы снизили влияние признака “широта”. Но это было обусловлено его реальным физическим смыслом.
Правила безопасности
“Назначать” признаки в “парные” нужно очень осторожно и с четким пониманием исследуемой области.
Возьмем другой пример. Вы анализируете колебания некоего узла/датчика, закрепленного на вертикальном элементе в большом механизме. У Вас есть величины колебаний как “вправо-влево” (синие стрелки), так и “вперёд-назад” (оранжевые стрелки). Еще, из-за конструктивных особенностей механизма, колебания “вправо-влево” могут быть в несколько раз больше, чем “вперёд-назад”.
Вроде бы ситуация схожая с прошлой. Оба признака измеряются в миллиметрах. И вместе они составляют условные “координаты” узла при его колебаниях.
Но, допустим, оказывается (из-за тех же конструктивных особенностей), что сильные колебания “вперёд-назад”, пусть даже они по величине в разы меньше, чем “вправо-влево”, могут привести к поломке узла. Т.е. величина изменения у этого признака не равнозначна его “напарнику”.
В этом случае снижать влияние этого признака, как мы выше поступили с “широтой”, наоборот нельзя.
В общем, напоследок банальный совет — перед тем как начать какие-либо преобразования своих данных, не забудьте внимательно к ним присмотреться. Вдруг среди них есть что-то требующее чуть более индивидуального подхода.
Какие данные называют промежуточными
 Введение
Введение
Введение в программирование на языке Pascal
Работа с величинами. Ввод-вывод
Выражения. Линейные алгоритмы
Итак, с понятием величины связаны следующие характеристики (атрибуты):
Постоянной называется величина, значение которой не изменяется в процессе исполнения алгоритма, а остается одним и тем же, указанным в тексте алгоритма. Переменной называется величина, значение которой меняется в процессе исполнения алгоритма.
Тип выражения определяется типами входящих в него величин, а также выполняемыми операциями. В языке Pascal тип величины задают заранее, т.к. все переменные, используемые в программе, должны быть объявлены в разделе описания с указанием их типа.
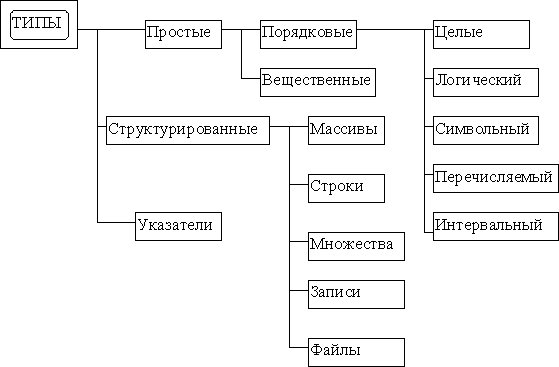
Различают переменные следующих простых типов: целые (Integer, Byte, ShortInt, Word, LongInt), вещественные (Real, Comp, Double, Single, Extended), логический (Boolean), символьный (Char), перечисляемый, диапазонный.
Вообще, иерархия типов в языке Pascal следующая:
Объявления служат для компилятора источником информации о свойствах величин, используемых в программе, и установления связи между этими величина и их идентификаторами, фиксируя тем самым конкретный смысл, предписанный различным идентификаторам в программе. Согласно объявленным переменным и их количеству компилятор резервирует необходимый объем памяти для хранения значений величин, над которыми выполняются требуемые операции.
Описание переменной: имя переменной (идентификатор) : тип;
Каждый тип имеет свой идентификатор.
Обмен информацией с ЭВМ предполагает использование определенных средств ввода-вывода. В ЭВМ основным средством ввода является клавиатура, вывода — дисплея.
В языке Pascal эта команда выглядит следующим образом:
В списке ввода значения разделяются между собой пробелом. Присваивание значений из входного потока выполняется слева направо в соответствии с порядком следования переменных в процедуре Read. Процедура ReadLn похожа на Read. Разница лишь в том, что ReadLn реагирует на конец строки, и в случае его обнаружения происходит сразу переход к следующей строке.
Примеры ввода данных с помощью процедуры ReadLn:
Процедура, которая выводит содержимое переменных на экран, называется процедурой вывода на экран.
В Pascal эта команда выглядит следующим образом
Write (список констант и/или переменных, разделенных запятой)
В списке вывода этих операторов может быть либо одно выражение, либо последовательность таких выражений, разделенных между собой запятыми.
Процедура Write осуществляет вывод значений выражений, приведенных в его списке, на текущую строку до ее заполнения. С помощью процедуры WriteLn реализуется вывод значений выражений, приведенных в его списке, на одну строку дисплея и переход к началу следующей строки.
Примеры вывода данных:
Для управления размещением выводимых значений процедуры Write и WriteLn используются с форматами. Под форматом данных понимается расположение и порядок кодирования отдельных полей элементов данных.
Процедура вывода с форматом для целого типа имеет вид:
При выводе вещественных значений оператор Write(R) без указания формата выводит вещественное R в поле шириной 18 символов в форме с плавающей запятой в нормализованном виде. Для десятичного представления значения R применяется оператор с форматами вида WriteLn(R : N : M). В десятичной записи числа R выводится M (0 Ј M Ј 24) знаков после запятой, всего выводится N знаков.
Общая структура программы на Pascal такова:
Оператор присваивания — один из самых простых и наиболее часто используемых операторов в любом языке программирования, в том числе и в Pascal. Он предназначен для вычисления нового значения некоторой переменной, а также для определения значения, возвращаемого функцией. В общем виде оператор присваивания можно записать так:
Оператор выполняется следующим образом. Вычисляется значение выражения в правой части присваивания. После этого переменная, указанная в левой части, получает вычисленное значение. При этом тип выражения должен быть совместим по присваиванию с типом переменной. Тип выражения определяется типом операндов, входящих в него, и зависит от операций, выполняемых над ними.
Для операций сложения, вычитания и умножения тип результата в зависимости от типа операнда будет таким:
| Операнд 1 | Операнд 2 | Результат |
| Integer | Integer | Integer |
| Integer | Real | Real |
| Real | Integer | Real |
| Real | Real | Real |
Для операции деления тип результата в зависимости от типа операнда будет таким:
| Операнд 1 | Операнд 2 | Результат |
| Integer | Integer | Real |
| Integer | Real | Real |
| Real | Integer | Real |
| Real | Real | Real |
В Pascal есть операции целочисленного деления и нахождения остатка от деления. При выполнении целочисленного деления (операция DIV) остаток от деления отбрасывается.
Например, 15 div 3 = 5; 18 div 5 = 3; 123 div 10 = 12, 7 div 10 = 0.
С помощью операции MOD можно найти остаток от деления одного целого числа на другое.
Например, 15 mod 3 = 0; 18 mod 5 = 3; 123 mod 10 = 3, 7 mod 10 = 7.
При записи алгебраических выражений используют арифметические операции (сложение, умножение, вычитание, деление), функции Pascal, круглые скобки.
Порядок действий при вычислении значения выражения:
1) вычисляются значения в скобках;
2) вычисляются значения функций;
3) выполняется унарные операции (унарный минус — смена знака);
4) выполняются операции умножения и деления (в том числе целочисленного деления и нахождения остатка от деления);
5) выполняются операции сложения и вычитания.
Встроенные математические функции языка Pascal
| Математическая запись | Запись на Pascal | Назначение |
| cos x | cos(x) | Косинус x радиан |
| sin x | sin(x) | Синус x радиан |
| e x | exp(x) | Значение e в степени x |
| [ x ] | trunc(x) | Целая часть числа x |
| | x | | abs(x) | Модуль числа x |
| x 2 | sqr(x) | Квадрат числа x |
| sqrt(x) | Квадратный корень из x | |
| frac(x) | Дробная часть x | |
| arctg x | arctan(x) | Арктангенс числа x |
| ln x | ln(x) | Натуральный логарифм x |
| p | Pi | Число p |
Примеры записи математических выражений:
Логический операнд — это конструкция соответствующего языка программирования, которая задает правило для вычисления одного из двух возможных значений: True или False.
Чаще всего логические выражения используют в операторах присваивания или для записи того или иного условия. Составными частями логических выражений могут быть: логические значения (True, False); логические переменные; отношения.
В языке Pascal операции отношения определены для величин любого порядкового типа (целые, символьный, логический, перечислимый, диапазон). Операции отношения могут быть выполнены также над строковыми выражениями. Сравнение двух строк выполняется посимвольно слева направо в соответствии с их лексикографической упорядоченностью в таблице кодов ASCII. Эта упорядоченность предполагает, что «1» Логическое выражение — это логический операнд или последовательность логических операндов, разделенных между собой знаками логических операций (NOT, AND, OR, XOR).
Порядок действий при вычислении значения логического выражения:
1) вычисляются значения в скобках;
2) вычисляются значения функций;
3) выполняется унарные операции (операция NOT);
4) выполняется операция AND;
5) выполняются операции OR, XOR;
6) выполняются операции отношения.
Действия выполняются слева направо с учетом их старшинства. Желаемая последовательность операций обеспечивается путем расстановки скобок в соответствующих местах выражения.
При реализации некоторых программ удобно использовать функции, которые имеют логическое значение. Обычно они используются для того, чтобы на некоторый вопрос получить ответ “ДА” или “НЕТ”.
Например, следующая функция возвращает True, если её аргумент — простое число, и False — в противном случае:
Рассмотрим примеры задач, где алгоритм решения является линейным.
Задача 1. Скорость первого автомобиля v 1 км/ч, второго — v 2 км/ч, расстояние между ними s км. Какое расстояние будет между ними через t ч, если автомобили движутся в разные стороны?
Согласно условию задачи искомое расстояние s 1 = s +( v 1 + v 2 ) t (если автомобили изначально двигались в противоположные стороны) или s 2 =|( v 1 + v 2 ) t-s| (если автомобили первоначально двигались навстречу друг другу).
Чтобы получить это решение, необходимо ввести исходные данные, присвоить переменным искомое значение и вывести его на печать.
Заметим, что идентификатор должен начинаться с латинской буквы, кроме латинских букв может содержать цифры, знак подчеркивания (_).
Разумно, чтобы программа вела диалог с пользователем, т.е. необходимо предусмотреть в ней вывод некоторых пояснительных сообщений. В противном случае даже сам программист может через некоторое время забыть, что необходимо вводить и что является результатом.
Для всех величин в программе объявлен тип Real, что связано со стремлением сделать программу более универсальной и работающей с как можно большими наборами данных.
Задача 2. Записать логическое выражение, принимающее значение TRUE, если точка лежит внутри заштрихованной области, иначе — FALSE.
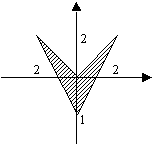
Прежде всего обратим внимание на то, что эту сложную фигуру целесообразно разбить на несколько более простых: треугольник, лежащий в I и IV координатных четвертях и треугольник, лежащий во II и III четвертях. Таким образом, точка может попасть внутрь одной из этих фигур, либо на линию, их ограничивающую. Количество отношений, описывающих какую-либо область, обычно совпадает с количеством линий, эту область ограничивающих. Чтобы точка попала внутрь области, необходима истинность каждого из отношений, поэтому над ними выполняется операция AND. Так вся область была разбита на несколько, то между отношениями, описывающими каждую из них, используется операция O R.
Учитывая приведенные здесь соображения и записав уравнения всех ограничивающих фигуру линий, получаем искомое логическое выражение:
Задача 3. Вычислить значение выражения
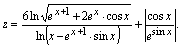
Для решения задачи достаточно ввести все данные, безошибочно записать выражение и вывести результат. Примечание. При решении этой задачи не учитывается область определения выражения, считается, что вводятся только допустимые данные.
Контрольные вопросы и задания
1. Что такое величина?
2. Какие величины называют аргументами? результатами? промежуточными величинами? Приведите примеры.
3. Каковы атрибуты величины?
4. Какие величины называют постоянными? переменными? Приведите примеры.
5. Какие простые типы величин существуют в языке Pascal?
6. Что определяет тип величины?
7. Расскажите о простых типах данных и их атрибутах.
8. Как осуществляется ввод данных в языке Pascal? Приведите примеры.
9. Как осуществляется вывод данных в языке Pascal? Приведите примеры.
10. Какова общая структура программы в языке Pascal?
11. Расскажите об операторе присваивания и совместимости типов.
12. Что такое формат вывода?
13. Расскажите о правилах вычисления алгебраического выражения. Приведите примеры.
14. Расскажите о правилах вычисления логического выражения. Приведите примеры.
15. Расскажите о логических операциях. Приведите примеры.
16. Приведите примеры задач, имеющих линейный алгоритм решения.
17. Определите, какой суммарный объём памяти требуется под переменные в каждом из примеров 1–3.
18. Каково назначение следующей программы?
20. Выпишите несколько алгебраических выражений и запишите их на языке Pascal.
21. Запишите алгебраические выражения, соответствующие следующим записям на языке Pascal:
а) (a + b) / c; б) a + b / c; в) a / b / c; г) a / (b * c);
Классификация таблиц в реляционных базах данных по признакам целостности и избыточности данных
Содержание статьи
Обоснование статьи и некоторые ключевые понятия;
1. Справочники и связки;
1.1. Виды таблиц;
1.2. Виды справочников;
1.3. Виды связок;
2. Обобщение классификации;
2.1. Классификация в табличном виде;
2.2. Классификация в схематичном виде;
3. Некоторые комментарии по применению классификации;
3.1. Применение классификации при нормализации таблиц;
Заключение.
Обоснование статьи и некоторые ключевые понятия
Очень часто присутствовал на обучении дисциплине «Базы данных». Обучался когда-то сам… Как-то даже пришлось проводить целый курс для друзей и знакомых. Во время обучения мною было замечено, что трудности возникают уже на этапе понимания таблиц и того, как ими пользоваться. Многие просто не могли и не могут разработать простейшие базы данных. После более детального рассмотрения такого понятия как таблицы и маленькой классификации, трудности восприятия таблиц в реляционных базах данных почти всегда исчезают. Итак!
В данной статье будет рассмотрена маленькая классификация таблиц по признакам целостности и избыточности. Что это значит? Это значит, что будут приведены примеры с описанием, какую структуру таблиц можно делать, чтобы предотвращать (пытаться предотвращать) избыточность и добиваться целостности в реляционных базах данных.
Для понимания дадим краткие определения целостности и избыточности данных:
Целостность данных – это свойство способности по одним данным восстанавливать другие, при этом не теряя семантическое единство этих данных и отношения между ними (между данными).
Избыточность данных – это состояние базы данных, при котором в таблицах присутствуют лишние данные.
Целостность данных может быть нарушена в результате операций модификации данных. Если в базе данных запрещены операции удаления и обновления, то целостность может быть нарушена только в результате операции добавления, а также неправильно написанных скриптов по отображению данных.
1. Справочники и связки
1.1. Виды таблиц
Немного углубимся в маленькую классификацию таблиц по видам их структуры. Разделим таблицы на два общих вида. Первым видом будут таблицы-справочники, вторым таблицы-связки.
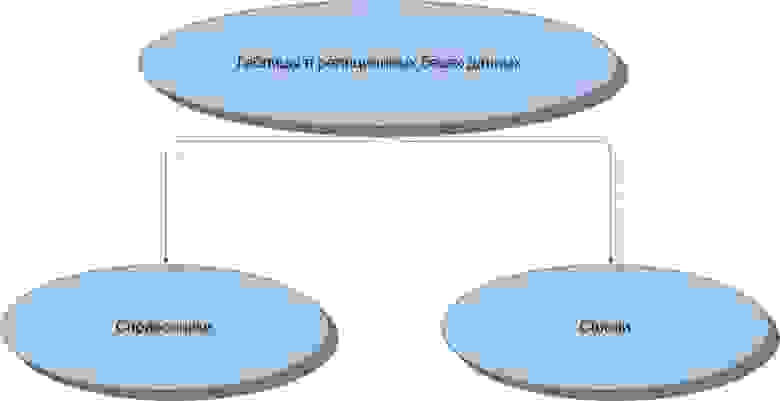
Рисунок 1. Справочники и связки
Информацию в таблицах можно разделить на два вида. На информацию, которая описывает объекты (субъекты), связи и информацию, которая описывает действия, процессы, события, иное.
В справочниках содержатся сведения об объектах и субъектах, связях. В связках содержатся сведения о действиях, процессах, событиях и так далее.
В связках хранятся данные, взятые из таблиц справочников. Поскольку невыгодно повторять одни и те же данные при описании объектов (субъектов) и при описании их взаимодействия, данные об объектах (субъектах) заносятся в справочники, а в таблицах-связках не хранятся данные объектов (субъектов) в чистом виде, а лишь ссылки на них (внешний ключ). Таким образом, в связках хранятся данные по взаимодействию объектов (субъектов) и ссылки на самих объектов (субъектов) (внешний ключ). Эти «ссылки» являются первичными ключами в таблицах справочниках. Но об этом потом…
Отличие справочника от связки выражается в том, что таблицы-справочники могут быть самостоятельными и независимыми (то есть, при чтении данных некоторых справочников можно в целом понять семантику), а таблицы-связки практически никогда.
1.2. Виды справочников
Справочники могут подразделяться на несколько видов. Это статичные, статично-динамичные и динамичные справочники. Разумеется, вряд ли можно назвать абсолютно статичный справочник, так как в этом мире может измениться всё. Или почти всё.
Статичный справочник – справочник, данные об объектах, субъектах, связях в котором либо никогда не подвергаются модификации после первичной модификации, либо настолько редко подвергаются модификации, что этим можно пренебречь.
Примером таких справочников могут служить список месяцев с названиями и номерами, список дней недели, список времён года, список океанов и так далее…
| Номер | Наименование |
| 1 | Январь |
| 2 | Февраль |
| 3 | Март |
| 4 | Апрель |
| 5 | Май |
| 6 | Июнь |
| 7 | Июль |
| 8 | Август |
| 9 | Сентябрь |
| 10 | Октябрь |
| 11 | Ноябрь |
| 12 | Декабрь |
Таблица 1. Пример статичных справочников
Статично-динамичный справочник – справочник, в котором хранятся данные о связях, если связи носят справочный характер. В таком справочнике могут быть внешние ключи.
Наиболее удачным примером будет таблица с такими медицинскими данными, как вес. Список человек, вес которых измеряется, изменяется не так часто. А вот данные по их весу могут меняться каждый день. Статично-динамичные справочники являются единственными справочниками, где осознанно можно повторять любую информацию. Ещё одним примером может быть справочник окладов по должностям (по коду должности).
| Код должности | Оклад | Дата обновления |
| 1001 | 12 000 | 05.02.2015 |
| 1002 | 17 000 | 01.02.2015 |
| 1003 | 11 500 | 01.02.2015 |
| 1004 | 25 450 | 01.02.2015 |
| 1005 | 10 000 | 01.02.2015 |
| 1006 | 6 000 | 04.02.2015 |
Таблица 2. Пример статично-динамичных справочников
Динамичные справочники – это таблицы, данные об объектах, субъектах, связях в которых меняются часто и используются в других таблицах. От статичных справочников отличаются только частотой модификации в них данных.
Примером таких таблиц могут быть списки проектов. На самом деле, данные об открытии или закрытии проектов могут находиться в самом справочнике проектов, что в большинстве случаев неправильно и нарушает целостность. С другой стороны, если хранить историю изменений по открытию и закрытию (приостановке) проектов, то можно получить избыточность данных. Целостность и избыточность данных будут бороться с друг другом ещё долго, также как и зима с летом.
| Код проекта | Проект | Нормативный срок выполнения | Дата добавления | Пользователь |
| PT102 | Покраска окон | 15 | 03.01.2014 | 1547 |
| PT103 | Установка дверей | 10 | 04.01.2014 | 9874 |
| PT587 | Проверка пожарных кранов | 2 | 04.01.2014 | 1456 |
| PT588 | Замена люков | 3 | 02.01.2014 | 0147 |
| PT133 | Очистка каналов | 11 | 09.02.2015 | 1547 |
Таблица 3. Пример динамичных справочников
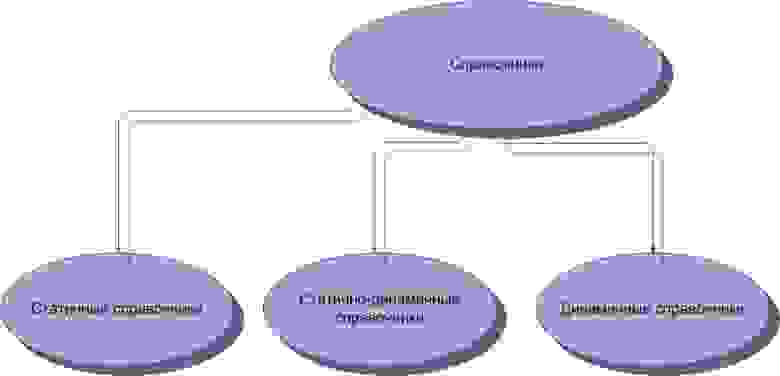
Рисунок 2. Виды справочников
1.3. Виды связок
Таблицы-связки можно разделить на два вида.
Это справочник-связка (сразу же уточним, что справочник-связка справочником не является, назван так, потому что в нём существуют поля, которые образуют справочник, но в справочник выделены быть не могут). Таблица, в которой хранятся внешние ключи, данные, которые не являются справочными и поля, содержащие данные, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник.
Примером справочника-связки будет являться таблица платёжных транзакций. Или таблица с данными о футбольном матче.
| Код транзакции | Плательщик | Получатель | Сумма | Дата | Комментарий |
| EEVS-doodi4 | 100045 | 57457 | -10 000 | 25.07.2014 | На сапоги |
| UDFD-ioeed9 | 455780 | 10024 | -900 | 24.06.2014 | NULL |
| PEDD-jdksl4 | 144770 | 56698 | -6980 | 01.01.2015 | NULL |
| FDFE-keiiii0 | 447757 | 1 | 120 | 08.07.2014 | NULL |
Таблица 4. Пример справочника-связки
И связка (да, просто связка). Это таблица в которой хранятся только внешние ключи и данные, которые нельзя отнести к справочным, например дата или значения логических полей.
Примером связки будет являться таблица автоматического логирования терминала обработки данных.
Кстати, легко догадаться, что связки почти нигде не используются, поскольку чаще всего находятся данные, которые могут быть записаны в базу, но не содержаться в справочниках, поэтому невозможно сопоставить им внешний ключ.
| Код | Код клиента | Показания счётчика | Месяц |
| 2334 | 35643 | 50 | 01.01.2015 |
| 2335 | 235673 | 49 | 01.01.2015 |
| 2335 | 436345 | 56 | 01.01.2015 |
| 2335 | 574733 | 24 | 01.01.2015 |
Таблица 5. Пример связки
Необходимо пояснить, что это за поля, которые образуют справочник, но не могут быть выделены в отдельную таблицу-справочник. Примером таких полей являются поля «комментарий», «жалоба», «описание», «предложение». Словом, если приводить популярный пример, то поле «сообщение» в таблице базы данных любой социальной сети…
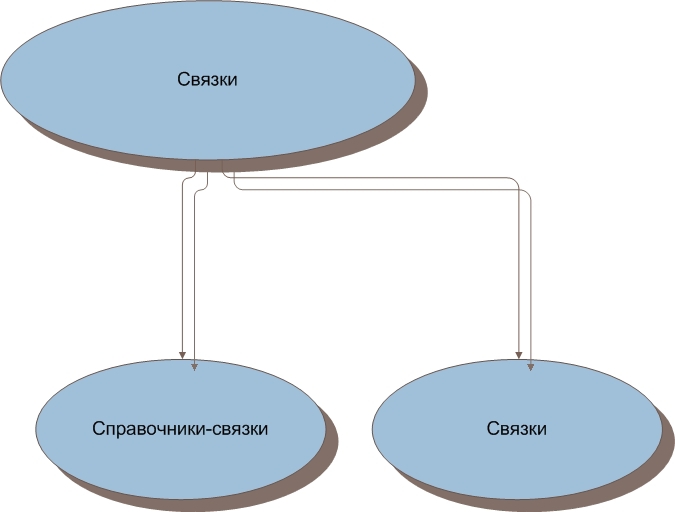
Рисунок 3. Виды связок
2. Обобщение классификации
2.1. Классификация в табличном виде
| Вид таблицы | Описание | Примеры | Плюсы (+) | Минусы(-) |
| Статичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В статичном справочнике должна содержаться информация, которая либо вообще не изменяется, либо изменяется так редко, что этим можно принебречь. На статичный справочник ссылаются (внешний ключ), когда нужно получить названия, обозначения, нормы, количественные или качественные показатели. Иное. | Справочник (наименований и номеров) месяцев. Справочник складов и цехов предприятия. Справочник правил игры. | Иногда заменяет системные функции СУБД, позволяет более гибко работать с некоторыми данными. В случае, если меняется редко изменяемая информация, предостерегает от серьёзных последствий. | Использование таблицы с любой структурой может замедлять работу, в случае, если таблица заменяет системное хранилише. Приходится писать дополнительные функции и обработки для данной таблицы, которые не всегда правильно оптимизированны. В некоторых случаях невозможно оптимизировать. |
| Статично-динамичный справочник | Таблица. Данные из неё берутся для других таблиц. Из справочника в других таблицах нельзя использовать внешний ключ этого справочника, однако можно использовать первичный ключ. | Справочник окладов по должностям. Справочник (размеров обуви, веса, роста, размера головы) физиологических параметров. Справочник (менеджеров, компаний) содержащий компании и менеджеров, которые эти компании обслуживают и учитывают. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник, выделенный из справочника-связки, никуда не девается и не имеет никакой реляционной связи, которая позволила бы ему превратиться в статичный или динамичный справочник. А значит, всегда избыточен. |
| Динамичный справочник | Таблица. Данные из неё берутся часто для других таблиц. Из справочника в других таблицах можно использовать только первичный ключ. В динамичном справочнике должна содержаться информация, которая часто изменяется. | Справочник клиентов. Справочник поставщиков. Справочник контрагентов. Справочник менеджеров компании. Справочник работников. Справочник студентов. | Позволяет хранить динамичные данные, при этом давая возможность однозначно ссылаться на них. | Чаще всего накопительного типа и не делим, что создаёт определённую избыточность. |
| Справочник-связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. | Платёжные транзакции. Продажи. Межзаводские перемещения. График перевозок. | Позволяет проводить гибкую нормализацию по схеме «Справочник-связка» = «Связка»+«Статично-динамичный справочник». | Справочник-связка после нормализации превращается в связку и сводит избыточность данных к минимуму, не затрагивая целостность, однако не делим и при архивировании в текущей таблице не подлежит оптимизации. |
| Связка | Таблица. Данные из неё не могут содержаться в других таблицах, но на основе них могут быть созданы данные в других таблицах. Таблица не может содержать кортежей, значения атрибутов в которых являются неделимыми и не уникальными. | Автоматический лог ошибок в программе. Лог запроса сервера. Результаты трассировок. Отчёты о выгрузке и загрузке компонентов. Автоматические отчёты системы безопасности. | Связка сводит избыточность данных к минимуму, не затрагивая целостность. | Накапливаясь, является неделимой таблицей. Сложно оптимизировать. |
Таблица 6. Классификация
2.2. Классификация в схематичном виде
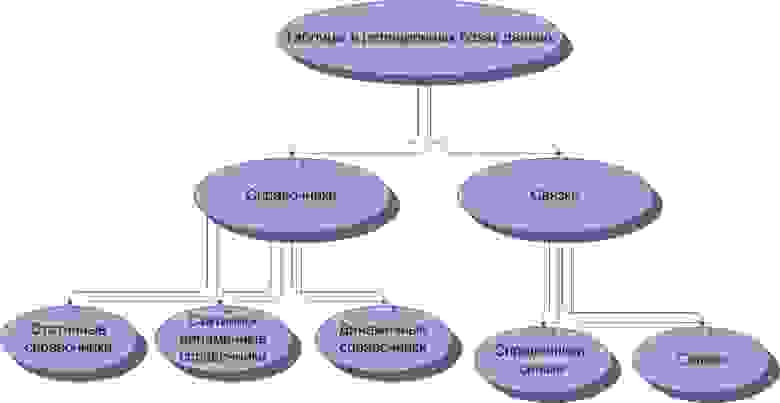
Рисунок 4. Схема классификации таблиц в реляционных базах данных по признакам целостности и избыточности данных
3. Некоторые комментарии по применению классификации
3.1. Применение классификации при нормализации таблиц
Процесс нормализации, если не учитывать некоторые этапы (Но учитывать результаты этих этапов!) — это обычное «дробление» таблиц на более мелкие таблицы с созданием реляционной связи между ними непосредственно или через промежуточные таблицы (связь «Многие ко многим»). Под реляционной связью может не всегда пониматься реляционное отношение!
Преобразование динамичного или статичного справочника в статично-динамичный справочник, а справочника-связки в связку, как и статично-динамичного справочника в справочник-связку — это ни что иное, как дробление таблиц. То есть, преобразование одного вида таблиц в другой через показанную выше классификацию в целях избежания избыточности данных — так можно определить нормализацию (один из вариантов определения).
Для примера. Пусть имеется база данных, в которой единственная операция по модификации данных — это добавление. В таком случае становится неэффективным каждый раз при изменении какого либо отдельного атрибута сущности, «копировать» остальные значения атрибутов уже в другой кортеж. В этом случае используются NULL или же создание статично-динамичного справочника, где описывается ряд атрибутов одной семантики или один атрибут, а дублируется лишь внешний ключ с первичным ключом последовательности. Этот же метод может использоваться в традиционной схеме модификации данных с обновлением и удалением данных.
Заключение
Данная классификация была создана мной на основе наблюдений при проектировании баз данных, а также исходя из прочитанной теории по проектированию в реляционных СУБД. Моим друзьям и знакомым, изучающим дисциплину «базы данных» и занимающимся проектированием баз данных, и мне эта классификация достаточно серьёзно упростила «жизнь» и позволила во многих ситуациях заранее выбрать наиболее подходящий и, как оказывалось потом, правильный вид таблицы для хранения в ней тех или иных данных.
Классификация может быть расширена разделением существующих видов в ней на подвиды (возможно, даже, добавлением новых видов). Также эта классификация показала, что лучше в некоторых ситуациях не использовать тот или иной вид таблиц. Некоторые виды таблиц из данной классификации лучше использовать реже (динамичные справочники). А некоторые пытаться заменить на другие (справочники-связки на связки).
Надеюсь, кому ни будь ещё поможет эта классификация при освоении дисциплины «Базы данных» и при проектировании баз данных в реляционных СУБД.



